
Exploring Author Gender in Book Rating and
Recommendation
Michael D. Ekstrand and Daniel Kluver
Feb. ,
Author’s Accepted Manuscript. is is a post-peer-review, pre-copyedit version of an ar-
ticle published in User Modeling and User-Adapted Interaction. e final authenticated version
is available online at: https://dx.doi.org/10.1007/s11257-020-09284-2. Read free
via ShardIt at https://rdcu.be/ceNgJ.
Please cite as:
Michael D. Ekstrand and Daniel Kluver. . Exploring Author Gender in Book Rating
and Recommendation. User Modeling andUser-Adapted Interaction. DOI ./s--
-. Retrieved from https://md.ekstrandom.net/pubs/bag-extended.
Abstract
Collaborative filtering algorithms find useful patterns in rating and consumption data and
exploit these patterns to guide users to good items. Many of these patterns reflect important
real-world phenomena driving interactions between the various users and items; other pat-
terns may be irrelevant or reflect undesired discrimination, such as discrimination in pub-
lishing or purchasing against authors who are women or ethnic minorities. In this work, we
examine the response of collaborative filtering recommender algorithms to the distribution of
their input data with respect to one dimension of social concern, namely content creator gen-
der. Using publicly-available book ratings data, we measure the distribution of the genders
of the authors of books in user rating profiles and recommendation lists produced from this
data. We find that common collaborative filtering algorithms tend to propagate at least some
of each user’s tendency to rate or read male or female authors into their resulting recommen-
dations, although they difer in both the strength of this propagation and the variance in the
gender balance of the recommendation lists they produce. e data, experimental design, and
statistical methods are designed to be reusable for studying potentially discriminatory social
dimensions of recommendations in other domains and settings as well.
1 Introduction
e evaluation of recommender systems has historically focused on the accuracy of recommen-
dations [Herlocker et al., , Gunawardana and Shani, ]. When it is concerned with other
characteristics, such as diversity, novelty, and user satisfaction [Hurley and Zhang, , Ziegler
et al., , Knijnenburg et al., ], it oten continues to focus on the system’s ability to meet
traditionally-understood information needs. But this paradigm, while irreplaceable in creating
products that deliver immediate value, does not tell the whole stor y of a recommender system’s
interaction with its users, content creators, and other stakeholders.
In recent years, public and scholarly discourse has subjected artificial intelligence systems to
increased scrutiny for their impact on their users and society. Much of this has focused on clas-
sification systems in areas of legal concern for discrimination, such as criminal justice, employ-
ment, and housing credit decisions. However, there has been interest in the ways in which more
consumer-focused systems, such as matching algorithms [Rosenblat and Stark, , Hannak
et al., ] and search engines [Magno et al., ], interact with issues of bias, discrimination,
and stereotyping.
Social impact is not a new concern in recommender systems. Balkanization [van Alstyne and
Brynjolfsson, ] (popularized by Pariser [] as the notion of a filter bubble), is one example of
this concern: do recommender systems enrich our lives and participation in society or isolate us
in echo chambers? Understanding the ways in which recommender systems actually interact with
past, present, and future user behavior is a prerequisite to assessing the ethical, legal, moral, and
social ramifications of their influence.
In this paper, we present experimental strategies and obser vational results from our investi-
gation into how recommender systems interact with author gender in book data and associated
consumption and rating patterns. e direct experimental outcomes of this paper characterize
the distribution of author genders in existing book data sets and the response of widely-used col-
laborative filtering algorithms to that distribution, and assess the accuracy impact of deploying
eficient strategies for adjusting the gender makeup of recommendation lists. e data and meth-
ods that we have used for this paper, however, extend beyond our immediate questions and we
expect them to be useful for much more research on fairness and social impacts of recommender
systems. Our data processing, experiments, and analysis are all reproducible from public data
sets with the code accompanying this paper.
Our experiments address the following questions:
RQ1 How are author genders distributed in book catalog data?
RQ2 How are author genders distributed in users’ book reading histories?
RQ3 What is the distribution of author genders in recommendations generated by common col-
laborative filtering algorithms? is measures the overall behavior of recommender algo-
rithm(s) with respect to author gender.
RQ4 How do individual users’ gender distributions propagate into the recommendations that
they receive? is measures the personalized gender behavior of the algorithms.
RQ5 What control can system developers exert over recommendation distributions, and at what
cost?
While we expect recommender algorithms to propagate patterns in their input data, due to
the general principle of “garbage in, garbage out”, the particular ways in which those patterns do
or do not propagate through the recommender is an open question. Recommender systems do
not always propagate all patterns from their input data [Channamsetty and Ekstrand, ], and
it is important to understand how this (non-)propagation relates to matters of social concern.
1.1 Motivation and Fairness Construct
e work in this paper is motivated by our concern for issues of representation in book author-
ship. ere are eforts in many segments of the publishing industr y to improve representation
of women, ethnic minorities, and other historically underrepresented groups. Multiple organi-
zations undertake counts of books and book reviews to assess the representation of women and
nonbinary individuals in the literary landscape [Pajović and Vyskocil, , VIDA, ].
Our goal is to understand how recommendation algorithms interact with these eforts. Do
recommender systems help these authors’ work find the audience that will propel them to success?
Are they neutral paths, neither helping nor hindering? Or is algorithmic recommendation another
hurdle to their success, stacking the deck in favor of well-known authors and the status quo of the
publishing industr y?
Author representation also has a consumer-facing dimension: what picture does a book ser-
vice’s discovery layer paint of the space of book authorship? When a user is looking for books, do
they see books by a diverse range of authors, or are the books that are surfaced focused on certain
corners of the authorship space? is is admittedly a complex question, because recommending
books that are not relevant to a user’s interests or information need just because of their author’s
demographics does not make for an efective recommendation or information retrieval system.
Fairness in recommendation needs to be understood in the context of accuracy and other mea-
sures of efectiveness.
We study this in the context of user-provided ratings and interactions collected from three
sites widely used by readers. Amazon ratings are provided by Amazon users and are accompanied
by textual reviews (not used in the present work) to help prospective purchasers decide whether or
not to purchase a book. GoodReads and BookCrossing are reader communities, where readers cat-
alog books they have read or wish to read, rate books, and interact with other readers. GoodReads
makes extensive use of a social network, where people can form friendships to see each others’
book activities, ask for personal recommendations from friends, and provide reviews to help give
other readers insight into a book; the fundamental action is to add a book to a shelf, oten one
of “read”, “to-read”, or “currently-reading”; when adding a book to the “read” shelf, the user may
also provide a rating and a textual review. In addition to the social discovery mechanisms pro-
vided by the news feed, the makeup of users’ shelves is used as input to GoodReads’ recommender
algorithms.
e experiments in this paper are focused on consumer-centered provider fairness. Our framing is
similar to “calibrated fairness” proposed by Steck [], in that we are concerned with the makeup
of recommendation lists and their connection to users’ input profiles. While there are many ways
of conceiving of provider fairness, some of which we examine in Section ., list composition
seems particularly well-suited to understanding representation as it is experienced by users of

Book
Catalog
User 1
User 2
User n
User 1
User 2
User n
U1 Recs
U2 Recs
Un Recs
U1 Recs
U2 Recs
Un Recs
Recommender
Algorithm
RQ 1 RQ 2 RQ 3, 5
RQ 4
Figure : Experiment architecture and data flow.
the system. While our measurements focus on representation, we are measuring representation
in the context of recommendation lists that have been optimized for relevance to a user’s reading
preferences, thus implicitly accounting for accuracy.
e purpose of this paper is not to make any normative claims regarding the distributions we
observe, simply to describe the current state of the data and algorithms. We do not currently have
suficient data to determine whether the distributions obser ved in available data indicate under-
or over-representation, or what the “true” values are. We hope that our observations can be com-
bined with additional information from other disciplines and from future work in this space to
develop a clearer picture of the ways in which recommender systems interact with their surround-
ing sociotechnical ecosystems. Our normative claim is that researchers and practitioners should
care and seek to understand how their systems interact with these issues. Our methods provide a
starting point for such experiments.
1.2 Contributions and Summary of Findings
In the main body of the paper, we provide a detailed and comprehensive account of our data and
research methods. Figure shows the stages of the book recommendation pipeline that forms the
backbone of our experimental design, with how our research questions map to each stage. In this
section, we summarize our contributions and key findings to provide a roadmap for the rest of
the paper.
We operationalize gender balance as the fraction of books written by female authors, ater
discarding books for which we could not determine the author’s gender identity. Justification and
limitations of this decision are discussed in Section .. is is an obser vational and correlational
study. Our goal here is to understand what correlations exist; future work will explore additional
variables such as genre to better understand why the patterns we obser ve exist.
1.2.1 Findings
RQ1: Gender in Book Catalogs. .% of books in the Librar y of Congress for which we could
determine the author’s gender identity are written by women. Discover y platform book cata-
logs show higher representation of women: .% of known-gender Amazon books and .% of
known-gender GoodReads books are written by women. We therefore see an improvement in the
representation of female authors through the early stages of the pipeline as we move from pres-
ence in a generic catalog to presence in collaborative filter inputs. Section . and its supporting
figures describe these results.
In the context of a recommendation application, this finding describes the makeup of the set
of books that are available to be recommended.
RQ2: Gender inUser Profiles. ere is high variance between users’ author gender balances, but
the mean balance is approximately the same as the balance of the underlying set of books. is
variation could be the result of many factors beyond the scope of this paper, but it is unsurprising
that diferent users have diferent rating patterns. It has the benefit of providing a wide range
of actual user profiles for which to test the response of components further down the pipeline.
Section . describes these results.
With this finding, we understand more about the individual user histories that make up the
training data for the recommender system. Many recommenders, but particularly collaborative
filters, will try to learn and replicate the patterns in these profiles.
RQ3: Gender in Recommendations. Recommendation lists were comparable to user profiles in
terms of both mean and variance of their gender balances, with a few exceptions. Distribution
shapes, however, were markedly diferent, with some conditions favoring more extreme recom-
mendation outcomes than the input user profiles. Section . describes these results.
With this we see the makeup of individual recommendation outputs, to understand what view
of the book space the recommender is likely to provide to its users on average.
RQ4: Recommender Response to User Profile. Most algorithms we tested propagate users’ in-
put profile balances into their recommendation lists, particularly when operating in “implicit-
feedback mode” (where we only consider whether a user has interacted with a book, not how much
they liked it). Users who read more books by women were recommended more books by women.
is shows that author gender is correlated with one or more features that drive users’ consump-
tion patterns and result in patterns that the collaborative filter captures and reflects, or it is di-
rectly one of those features. It also means, however, that a user reading mostly books by authors
of one gender will likely receive recommendations that reinforce that tendency unless compen-
sating measures are deployed. Section . describes these results.
is question gets to how the recommender’s personalization capabilities respond to each
user’s individual tendency towards authors of a particular gender. How much of the patterns that
it sees does it replicate?
RQ5: Controlling Recommendation Representation. We designed simple re-ranking strategies
to force recommendation lists to meet particular balance goals, such as gender parity or a gender
balance that reflects the user’s rating profile. ese rerankings induce little loss in recommenda-
tion accuracy (as measured with mean reciprocal rank in a train-test evaluation). is suggests
that, if a system designer wishes, the gender balance of recommended items can be tuned with
little cost rather than accepted as the natural consequence of the data and algorithms. Section
discusses these results.
1.2.2 Methodological Contributions
DataIntegration. We describe an integration of six diferent public data sources — three datasets
of user-book consumption or preference records, and three sources of book and author metadata
— to study social issues in book recommendation, cataloging and justifying the data linking deci-
sions we made along the way. We expect this composite data set to be useful for further research
on reader-book interactions. Our integration strategy also ser ves as a case study in obtaining and
preparing data for fairness and social impact research, as data collection eforts for similar studies
in other domains and applications will need to make similar kinds of decisions. Section describes
the data pipeline in detail.
Experimental Methodology. Rigorous, reusable statistical methodologies for analyzing bias in
personalization algorithms are still in their infancy. We describe an end-to-end experimental
pipeline and statistical analysis for studying representation and list composition in recommen-
dation, and how user patterns do or do not propagate into recommendation outputs. We expect
the approach we take to be useful in studying equity in other recommendation and information
retrieval settings, and may be more broadly useful as well. Section describes the experimental
pipeline.
2 Background and Related Work
Our present work builds on work in both recommender systems and in bias and fairness in algo-
rithmic systems more generally.
2.1 Recommender Systems
Recommender systems have long been deployed for helping users find relevant items from large
sets of possibilities, usually by matching items against users’ personalized taste [Ekstrand et al.,
, Adomavicius and Tuzhilin, ]. ey are deployed for boosting e-commerce sales, sup-
porting music and book discovery, driving continued engagement with news and social media,
and in many other contexts and applications. A recommendation problem, in the abstract, usu-
ally consists of items i ∈ I and users u ∈ U with recorded user-item interaction r
ui
∈ R oten in
the form of ratings or some equivalent derived from the user purchasing, consuming, or other-
wise expressing interest in the item [Ekstrand and Konstan, ]. Each user has a set R
u
⊆ R
of the ratings they have provided; for the purposes of this paper, we call this their user profile, as it
is the data a system such as GoodReads would typically store about a user’s consumption history
and use as the basis for their recommendations. Recommender system feedback is oten divided
into two classes: explicit feedback, such as -star ratings, is provided by the user to express their
preference for an item; implicit feedback comes from user actions that, in suficient quantity, in-
dicate preference but are taken for consumption purposes, such as listening to a song or marking
a book as “to-read”.
Of particular interest to our current work is collaborative filtering (CF) systems, which use pat-
terns in user-item interaction data to estimate which items a particular user is likely to find useful.
ese include both neighborhood-based approaches and latent factor models.
While recommender evaluation and analysis oten focuses on the accuracy or quality of rec-
ommendations [Herlocker et al., , Gunawardana and Shani, ], there has been significant
work on non-accuracy dimensions of recommender behavior. Perhaps the best-known is diversity
[Ziegler et al., ], sometimes considered along with novelty [Hurley and Zhang, , Vargas
and Castells, ]. Lathia et al. [] examined the temporal diversity of recommender systems,
studying whether they changed their recommendations over time.
Jannach et al. [] studied recommendation bias with respect to classes of items, particularly
around various levels of item popularity. eir work is similar in its goals to ours, in that it is
looking to understand what diferent recommendation techniques recommend, beyond whether
or not it seems to match the user’s preference. We extend this line of inquiry to the socially-salient
dimension of author gender.
2.2 Social Impact of Recommendations
Recommender systems researchers have been concerned for how recommenders interact with
various individual and social human dynamics. One example is balkanization or filter bubbles
[van Alstyne and Br ynjolfsson, , Pariser, ], mentioned earlier; recent work has sought
to detect and quantify the extent to which recommender algorithms create or break down their
users’ information bubbles [Nguyen et al., ] and studied the efects of recommender feedback
loops on users’ interaction with items [Hosanagar et al., ].
Other work seeks to use recommender technology to promote socially-desirable outcomes
such as energy savings [Starke et al., ], better encyclopedia content [Cosley et al., ], and
new kinds of relationships [Resnick, ]. Our work provides the exploratory underpinnings for
future work that may seek to use recommenders to specifically promote the work of underrepre-
sented authors, and results on a first-pass set of techniques for doing so; Mehrotra et al. []
provide an example of pursuing such ends in the music domain.
2.3 Bias and Fairness in Algorithmic Systems
Questions of bias and fairness in computing systems are not new; Friedman and Nissenbaum
[] considered early on the ways in which computer systems can be (unintentially) biased in
their design or impact. In the last several years, there has been increasing interest in the ways
that machine learning systems are or are not fair. Dwork et al. [] and Friedler et al. [] have
presented definitions of what it means for an algorithm to be fair. Feldman et al. [] provide
a means to evaluate arbitrar y machine learning techniques in light of disparate impact, a standard
for the fairness of decision-making processes adopted by the U.S. legal system.
Bias and discrimination oten enter a machine learning system through the input data: the
system learns to replicate the biases in its inputs. is has been demonstrated in word embeddings
[Bolukbasi et al., ] and predictive policing systems [Lum and Isaac, , Ensign et al., ],
among others.
Research has also examined how bias and potential discrimination manifest in the whole so-
ciotechnical system, studying platforms such as TaskRabbit [Hannak et al., ] and OpenStreetMap
[ebault-Spieker et al., ]. One recent notable study by Ali et al. [] found discriminatory
patterns in Facebook ad delivery, even when advertisers set neutral budgets and campaign pa-
rameters. Bias can also be deployed subtly, as in the decisions of some online dating platforms to
reflect presumed latent racial preferences into match recommendations even when users specify
that they have no racial preference for their dating partner [Hutson et al., ].
2.4 Fair Information Access
Burke [] lays out some of the ways in which questions of fairness can apply to recommender
systems. In particular, he considers the diference between “C-fairness”, in which consumers or
users of the recommender system are treated fairly, and “P-fairness”, where the producers of rec-
ommended content receive fair treatment. Burke et al. [] and Yao and Huang [] have pre-
sented algorithms for C-fair collaborative filtering, and Ekstrand et al. [] examine C-fairness
in the accuracy of recommendation lists.
Our present study focuses on P-fairness. is dimension is somewhat related to historical con-
cerns such as long-tail recommendation and item diversity [Jannach et al., ]. Kamishima et al.
[] and Beutel et al. [] have presented algorithms for P-fair recommendation; calibration
[Steck, ] can be viewed as another kind of provider fairness.
Biega et al. [] and Singh and Joachims [] provide metrics for assessing fair exposure
to providers; this metric assess whether providers are recommended an “appropriate” number of
times. Other approaches to assessing the fairness of rankings look at the makeup of the ranking
or prefixes thereof [Yang and Stoyanovich, , Sapiezynski et al., , Zehlike et al., ]; this
is closer to our present work, in which we tr y to understand how lists are composed from the
perspective of gender representation.
A range of approaches are valuable at the present stage of research in fair recommendation
and information retrieval, and provide varying perspectives on how to operationalize and assess
fairness. In this paper, we present an ofline empirical analysis of the calibrated provider fairness
of several classical collaborative filtering algorithms and their underlying training data.
2.5 Representation in Creative Industries
As noted in Section ., there are eforts to both improve and audit the representation of women,
ethnic minorities, and other historically underrepresented groups [Pajović and Vyskocil, ,
VIDA, ]. In addition to these general representation measurement eforts, Hu [] reports

that gender biases in book reviews difer from genre to genre; in particular, “Women are less likely
to receive reviews when writing about topics that aren’t deemed ‘feminine.”’. Bucur [] found
that users on Amazon are more likely to co-purchase books by female authors if they are buying
another book by a female author than if their initial book is by a male author, and elwall []
found that GoodReads users tend to give higher ratings to authors of their own gender.
Beyond books, Epps-Darling et al. [] studied gender representation in music streaming
and recommendation, finding that female or mixed-gender artists comprise only % of organic
plays, and a slightly higher fraction of recommender-driven plays. Concurrently with our ex-
panded work, Shakespeare et al. [] carried out an experiment similar to ours in music rec-
ommendation and found collaborative filtering algorithms also propagating listeners’ biases into
their recommendations.
3 Data Sources and Integration
Traditional recommender systems experiments typically rely on rating or consumption data. ere
is a wide range of such data sets publicly available, including movie ratings from MovieLens [Harper
and Konstan, ], product reviews from Amazon [McAuley et al., ], and artist play logs from
Last.fm [Celma, ]. Sometimes these data sets are augmented with additional data, such as
additional sources of item data or text crawled from Web pages. Studying fairness and other so-
cial dimensions of recommendation, however, require data that is not commonly provided with
rating data [Ekstrand et al., ], requiring some creativity.
Investigating how content creator demographics relate to recommendation requires the fol-
lowing classes of data:
• Consumptiondata on books users have read and/or rated, to understand reading patterns and
train recommendation algorithms.
• Book data describing books and, for our purposes, their authors.
• Author data describing the authors themselves, and including demographic characteristics
of interest.
Fig. shows how these types of data fit together and the data sets we use for each. Linking the
data sets together is not easy, due both to the messiness of the data itself (e.g. malformed ISBNs)
and the lack of linking identifiers.
is section provides details on our data integration, justifications of data linking decisions
we made, and descriptive statistics of the resulting composite data set.
3.1 User Profiles and Book Ratings
We us three public sources of user-book interactions. For each, we treat it both as an explicit feed-
back data set by consulting rating values, and as an implicit feedback data set by ignoring rating
Documentation and code available at https://bookdata.piret.info

UserProfiles
Amazon
BookCrossing
GoodReads
Books
Libraryof
Congress
OpenLibrary
Authors
VIAF
ISBN Name
Figure : Data set relationships.
Users Items Pairs Density
AZ ,, ,, ,, .%
BX-E , , , .%
BX-I , , ,, .%
GR-E , ,, ,, .%
GR-I , ,, ,, .%
Table : Interaction data summaries.
values and considering user-item interactions as positive signals. In implicit-feedback settings,
we consider all books a user has interacted with as positive implicit signals, even if they have a low
rating: this corresponds to the signal that a bookseller can derive from sales data, as they do not
know whether readers actually like the books they purchase once they have read them.
e BookCrossing (BX) data set [Ziegler et al., ] contains .M book interactions from the
BookCrossing reading community. is data set contains both explicit ratings, on a – scale,
and “implicit” actions of unspecified nature. Since not all ratings have rating values, for explicit-
feedback settings we exclude implicit actions, resulting in the “BX-E” data set; “BX-I” contains all
BookCrossing interactions without rating values.
e Amazon Books (AZ) data set [McAuley et al., ] contains .M reviews and ratings of
books provided by customers on Amazon.com. We use only the rating values, not the review text;
since all recorded interactions have rating values, we use the interactions as-is and do not need to
subset for explicit feedback.
e GoodReads (GR) data set [Wan and McAuley, ] contains M interactions including
ratings, reviews, and “add to shelf ” actions from GoodReads, a reading-oriented social network
and book discovery ser vice. As with BookCrossing, we extract a rating-only subset (“GR-E”) for
explicit-feedback analysis, and use all user-book interactions (“GR-I”) for implicit feedback.
ese data sets provide our historical user profiles (for RQ) and the training data for our col-
laborative filtering algorithms. All three are general reading data sets, consisting of user ratings
for books across a wide range of genres and styles. Table summarizes these data sets’ basic statis-

tics. e “Pairs” column indicates the number of unique user-item pairs that appear in the data
set. We resolve multiple editions of the same work into a single item (see Section .), so the item
counts we report here may difer slightly from the item counts reported in other uses of these same
rating data sets.
3.2 Book Bibliographic Records
We obtain book data, particularly author lists, by pooling records from Open Librar y
and the
Library of Congress (LOC) MARC Open-Access Records
.
We link these book records to rating data by ISBN. Both OpenLibrar y and LOC record ISBNs
for book entries, and all book rating sources record ISBNs for the books users interact with (in the
BookCrossing data, ISBN is the primar y key for books; Amazon uses ISBNs as the identification
numbers for books that have them).
Unfortunately, ISBN fields in the Library of Congress data are inconsistently formatted and
used, including ISBNs in a range of formats as well as text other than ISBNs (many book entries
store the cover price in the ISBN field). We use a regular expression to look for sequences of
or digits (allowing an X for the last digit in -digit sequences), optionally including spaces or
hyphens, and treated those as ISBNs. We do not validate check digits, preferring to maximize the
ability to match ISBNs in the wild.
3.3 ISBN Grouping
Books are oten released in multiple editions, each with their own ISBNs. ese can be diferent
formats of the same text — for example, hardcover and paperback editions of the same book will
have diferent ISBNs — or they can be revised and/or translated editions. Each edition, however,
is a version of the same creative work. To reduce data sparsity, improve data linking coverage, and
reflect a more accurate general-purpose recommendation scenario, we group related ISBNs into
a single “item”.
To group ISBNs, we form a bipartite graph of ISBNs and record IDs. Library of Congress
bibliography records, OpenLibrary “edition” records, and GoodReads book records all constitute
records for this purpose. In addition, OpenLibrary and GoodReads each have a concept of a “work ”;
when an edition or book is linked to a work, we use the work ID instead of the individual edition
or book ID. We then find the connected components on this graph, consider each component to
be an “item”, and assign it a single item identifier.
is process serves a similar purpose as ISBN linking ser vices such as thingISBN [Spalding,
] and OCLC’s xISBN ser vice, but is completely reproducible using open data sources. One
limitation of this technique is that some ISBNs link multiple creative works. is can happen via,
for example, in the case of multi-work collections with a single ISBN.
Rarely (less than % of ratings) this causes a user to have multiple ratings for a book; we resolve
multiple ratings in explicit-feedback settings by taking the median rating value. Taking the most
https://openlibrary.org/developers/dumps
https://www.loc.gov/cds/products/marcDist.php

recent rating would also be a reasonable option, but BookCrossing does not include timestamps;
since multiple ratings appear so infrequently, the precise strategy is unlikely to have significant
impact on our results.
3.4 Author Gender Data
We obtain author information from the Virtual Internet Authority File (VIAF)
, a directory of au-
thor information (Name Authority Records) compiled from authority records from the Library of
Congress and other libraries around the world. Author gender identity (MARC Authority Field
) is one of the available attributes for many records.
3.4.1 Gender Identity Coding
e MARC Authority Record data model [Librar y of Congress, ] employed by the VIAF is
flexible in its ability to represent author gender identities, supporting an open vocabulary and
begin/end dates for the validity of an identity. e Program for Cooperative Cataloging provides
a working group report on best practices for recording author gender identities, particularly for
authors who are transgender or have a non-binary gender identity [Billey et al., ].
Unfortunately, the VIAF does not use this flexibility — all its gender identity records are “male”,
“female”, or “unknown”. e result is that gender minorities are not represented, or are misgen-
dered, in the available data. We agree with Hofmann [] that this is a significant problem. e
Library of Congress records better data, and as of August is in the process of preparing new
exports of their linked data ser vies; we hope this will enable future research to better account for
the complex nature of human gender identity and expression.
3.4.2 Linking Author Data
Because OpenLibrar y, LOC, and VIAF do not share linking identifiers, we must link books to au-
thority records by author name. Each VIAF authority record can contain multiple name entries,
recording diferent forms or localizations of the author’s name. OpenLibrary author records also
carry multiple known forms of the author’s name. Ater normalizing names to improve matching
(removing punctuation and ensuring both “Last, First” and “First Last” forms are available), we
locate all VIAF records containing a name that matches one of the listed names for the first author
of any OpenLibrary or LOC records in a book ’s ISBN group. If all records that contain an assertion
of the author’s gender agree, we take that to be the author’s gender; if there contradicting gender
statements, we code the book ’s author gender as “ambiguous”.
We selected this strategy to balance good coverage with confidence in classification. Diferent
authors with the same full name but diferent genders are unlikely to be a common occurrence.
Less than .% of rated books have ‘ambiguous’ author genders. Table shows relative frequency
of link results for the books in our data sets; the columns correspond to the following failure points:
http://viaf.org/viaf/data/

Data Set No Bk No Auth No VIAF Unknown Ambig. Male Female
LOC — .% .% .% .% .% .%
AZ .% .% .% .% .% .% .%
BX-E .% .% .% .% .% .% .%
BX-I .% .% .% .% .% .% .%
GR-E — .% .% .% .% .% .%
GR-I — .% .% .% .% .% .%
Table : Summary of gender coverage (% of books with each resolution result).
. No Bk means the rating or interaction could not be linked to a book record of any kind.
GoodReads has % coverage since it comes with book records, but those records are not
used for any data other than record identifiers.
. No Auth means a book record was found, but had no authors listed.
. No VIAF means authors were found, but none could be matched to VIAF.
. Unknown means a VIAF record was found, but there were either no gender identity records
or all records said “unknown”.
. Ambiguous, Male, and Female are the results of actual gender identity assertions.
In the remainder of this paper, we group all no-data conditions together as “unlinked”; we
present coverage statistics across the pipeline to inform future reuse of the data set.
3.4.3 Coverage and Popularity
To better understand the relationship between coverage and item popularity, we examined the
distribution of gender resolution statuses for each item popularity percentile. Fig. shows these
results; more popular items are more likely to have gender identity information available. Further,
in Amazon and and GoodReads, female author representation seems to be better among the most
popular books than among the less-popular ones.
e precise implications of this need further investigation. One immediate implication is that
gender label coverage for books in users’ profiles is higher than it would be for books selected uni-
formly at random. is coverage increase also applies to the recommendations from algorithms
that tend to recommend more popular books. We expect that this popularity/coverage relation-
ship will be common not just in books but in many other content categories as well, because more
popular items are more likely to have broad attention and careful cataloging; items that are known
only to a small number of users are also more likely to be unknown to catalogers and metadata
curators. is has particular implications for studies looking at the fairness of long-tail recom-
mendations, as the system and experiment’s design would be pushing its results into portions of
the item space with lower label coverage for the fairness analysis.

0%
25%
50%
75%
100%
% of Books
AZ
Gender
male
female
ambiguous
unknown
unlinked
0%
25%
50%
75%
100%
BX-I
0 25 50 75 100
Item Popularity Percentile (100 is most popular)
0%
25%
50%
75%
100%
GR-I
Figure : Gender identity coverage by item popularity (as measured by number of interactions).
3.4.4 Alternative Approaches to Author Gender
Other work on understanding the behavior of computing systems with respect to gender and other
demographic attributes that have been the basis of historic and/or ongoing discrimination uses
various inference techniques to determine the demographics of data subjects. is includes sta-
tistical detection based on names [Mislove et al., ] and the use of facial recognition technology
[Riederer and Chaintreau, ].
Such sources, however, have been criticized as reductionistic [Hamidi et al., ] and oten
rely on and reinforce stereotypes regarding gender presentation. Further, even to the extent that
face-based gender recognition does work, it is biased in recognizing gender more accurately for
lighter-skinned subjects [Buolamwini and Gebru, ].
e Program for Cooperative Cataloging working group report specifically discourages infer-
ence of gender identity, even when the inference is performed by a human, admonishing cat-
alogers to “not assume gender identity based on pictures or names” [Billey et al., ]. Cata-
logers following the recommendations learn an author’s gender from explicit statements from of-
ficial sources regarding their gender, or from the choice of pronouns or inflected nouns in oficial
sources (such as the author’s biography on the book cover).
Given the technical challenges and ethical concerns raised by the prospect of gender inference,
and the recommendation of relevant working groups to avoid even human inference of gender,
we choose to forego inference techniques in favor of gender identities recorded by professional
catalogers.

0%
20%
40%
60%
% of Books or Ratings
12.6%
41.7%
1.0%
23.1%
21.6%
LOC
Books Ratings
9.5%
21.2%
0.8%
10.4%
58.1%
19.2%
29.2%
2.4%
9.2%
40.0%
AZ
0%
20%
40%
60%
24.0%
34.7%
2.4%
12.4%
26.5%
34.7%
41.4%
6.8%
6.9%
10.3%
BX-I
25.1%
36.9%
2.6%
11.1%
24.2%
32.5%
43.3%
7.1%
6.4%
10.7%
BX-E
F M Amb. UnK UnL
0%
20%
40%
60%
16.1%
25.5%
1.0%
8.9%
48.5%
37.6%
36.3%
7.1%
5.1%
13.9%
GR-I
F M Amb. UnK UnL
Gender
16.2%
25.5%
1.0%
8.9%
48.4%
37.4%
38.9%
9.6%
4.2%
9.9%
GR-E
Figure : Results of data linking and gender resolution. LOC is the set of books with Librar y of
Congress records; other panes are the results of linking rating data.
3.5 Data Set Statistics
Table and Fig. summarize the results of integrating these data sets. While the data is sparse, it
has suficient coverage for us to perform a meaningful analysis. We also report coverage of the Li-
brary of Congress data itself, as a rough approximation of books published irrespective of whether
they are rated. Unfortunately, we do not know what biases lie in the coverage rates: are unlinked
or unknown books more likely to be written by authors of one gender or another?
Consistent with , shows that ratings are concentrated on books with known author genders;
while almost % of GoodReads books are unlinked, less than % of interactions are with unlinked
books.

LOC AZ BX-I GR-I
Data Set
0%
25%
50%
75%
100%
% of Books
Gender
male
female
AZ BX-E BX-I GR-E GR-I
Data Set
0%
25%
50%
75%
100%
% of Ratings
Gender
male
female
Figure : Distribution of known-gender books in each data set.
Books Ratings
female male female male
DataSet
LOC .% .% — —
AZ .% .% .% .%
BX-E .% .% .% .%
BX-I .% .% .% .%
GR-E .% .% .% .%
GR-I .% .% .% .%
Table : Distribution of known-gender books and ratings.
Female Male
mean median mean median
Data Set
AZ . .
BX-I . .
GR-I . .
Table : Average interactions-per-item by gender.

3.6 RQ1: Baseline Corpus Distribution
is analysis, and the distribution of genders show in in Figs. – and Table , provide our answer
to RQ. Of Library of Congress books with known author genders, .% are written by women.
Rating data sets have higher representation of women: .% of books rated on Amazon are writ-
ten by women, and .% of BookCrossing books. Representation is higher yet when looking at
ratings themselves: while .% of known-gender books on GoodReads are written by women,
.% of shelf adds of known-gender books are for books by women. On average, books by female
authors are interacted with more frequently than books by male authors (on GoodReads, the me-
dian interaction count per item is for male-authored books and for female-authored books;
Table shows details). As seen in Fig. , the most popular books are relatively evenly split between
male and female authors in the book community sites (BookCrossing and GoodReads).
In general, we see the following progression in gender balance:
Books(LOC) < Books(platform) < ratings
Takeaway RQ1
If women are underrepresented in book publishing, they are less underrepresented in book
rating data, particularly at the top end of the book popularity scale. e GoodReads commu-
nity achieves close to gender parity in terms of books rated or added to shelves.
4 Experiment and Analysis Methods
Starting with the integrated book data, our main experiment has several steps:
. Sample users, each of whom has rated at least books with known author gender, for
analysis.
. Quantify gender distribution in sample user profiles (RQ).
. Produce recommendations for each sample users, using the entire data set for training.
. Compute recommendation list gender distribution (RQ) and compare with user profile dis-
tribution (RQ).
is experiment is completely reproducible with scripts available from the authors
combined
the integrated book data described in Section . An end-to-end re-run, not including data integra-
tion or hyperparameter tuning, took . hours (elapsed; . CPU-hours compute) on a cluster
node with two -core .GHz Xeon Gold processors and GiB of memory, and produced
approximately GiB of intermediate and output files.
https://md.ekstrandom.net/pubs/bag-extended
4.1 Sampling
We sample users to keep the final data set tractable. Our statistical analysis methods are
computationally intensive, scaling linearly in the number of users. Sampling users for assessing
user profile makeup and gender propagation enables this analysis to be done in reasonable time;
users is enough to ensure some statistical validity.
We require each user to have at least books with known author gender so that their profile
has enough books to estimate user gender balance, and so that the recommender has history with
which to make recommendations.
4.2 Recommending Books
We used the LensKit toolkit [Ekstrand, ] to produce recommendations for each of our
sample users using the following algorithms:
• UU, a user-based collaborative filter [Herlocker et al., ]. In implicit-feedback mode, it
sums user similarities instead of computing a weighted average.
• II, an item-based collaborative filter [Deshpande and Karypis, ]. As with UU, in implicit
feedback mode, this algorithm sums item similarities instead of computing a weighted av-
erage.
• ALS, a matrix factorization model trained with alternating least squares [Pilászy et al., ];
we use both implicit and explicit feedback versions.
• BPR, a learning-to-rank algorithm that optimizes pair wise ranking [Rendle et al., ]; we
use the BPR-MF version.
ese algorithms are intended to provide a representative sample of common recommenda-
tion paradigms; while there are many diferent algorithms for doing recommendation, they typ-
ically optimize either point-wise recommendation accuracy (like ALS) or ranking loss with a cost
function similar to that of BPR. We trained the collaborative filters over all available ratings, even
those for books with unknown genders, and only restricted recommendation lists to exclude already-
consumed books.
4.2.1 Tuning and Performance
While recommendation accuracy is not the focus of our experiment, we report it for context; it also
provides a baseline for our exploration of distribution-constraining rerankers in Section . Figure
shows the MRR both on the evaluation set and on the tuning set with the best hyperparameters.
Nearest-neighbor recommenders performed quite well on implicit-feedback data; we suspect this
is partially due to popularity bias [Bellogin et al., ], as similarity-sum implicit-feedback k-NN
will strongly favor popular items.
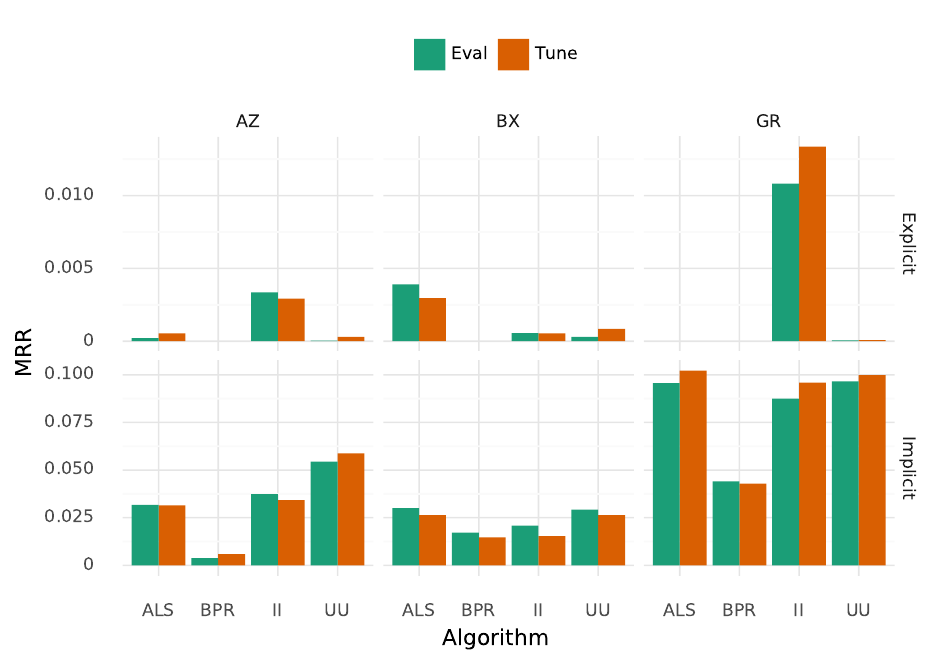
Figure : Top-N recommendation accuracy. Eval is the accuracy on the evaluation set, and Tune is
the best accuracy on the tuning set during hyperparameter tuning.

θ
u
y
u
n
u
µ σ
¯
θ
ua
ua
¯y
ua
¯n
ua
b
a
s
a
σ
a
u ∈ U
a ∈ A
Figure : Plate diagram for statistical model.
We sampled users with at least ratings for evaluation. For each user, we held out one
rating as the test rating, generated a -item recommendation list, and measured the Mean Re-
ciprocal Rank (MRR). We tuned each model’s hyperparameters with scikit-optimize, optimizing
MRR on a separate tuning set that was selected identically to the evaluation set.
We stopped tun-
ning when the best settings showed no more than % improvement in MRR. We exclude ALS on
GR-E because it did not perform well ater repeated tuning attempts. Implicit ALS worked well on
GoodReads.
4.3 Statistical Analysis
Our statistical goal is to estimate the gender balance of user profiles, recommendation lists, and
the propagation factor between them. ere are several challenges that complicate doing this with
commonly-used statistical techniques:
• Variance in user profile sizes makes it dificult to directly compare gender proportions be-
tween users ( out of and out of reflect very diferent levels of confidence).
• With many data sets and algorithm, we quickly run into large (and non-obvious) multiple
comparison problems.
• We are interested in assessing distributions of bias, not just point estimates.
To address these dificulties, we model user rating behaviors using a hierarchical Bayesian
model [Gelman et al., ] for the observed number of books by female authors out of the set of
books with known authors. is model allows us to integrate information across users to estimate
a user’s tendency even when they have not rated ver y many books, and integrated Bayesian models
enable us to robustly infer a number of parameters in a manner that clearly quantifies uncertainty
and avoids many multiple-comparison problems [Gelman and Tuerlinckx, ]. We extend this
To reduce the number of zeros, we tuned GoodReads using -item lists instead of .

Table : Summary of key model parameters and variables.
Variable Description
n
u
Number of known-gender books rated by
user u
y
u
Number of female-authored books rated by
u
θ
u
Probability of a known-author book rated by
u being by a female author (smoothed user
gender balance)
µ Expected user gender balance, in log-odds
(E[logit(θ
u
)])
σ
2
Variance of user gender balance
(var(logit(θ
u
)))
¯n
ua
Number of known-gender books algorithm
a recommended to user u
¯y
ua
Number of female-authored books a recom-
mended to u
¯
θ
ua
Gender balance of algorithm a’s recommen-
dations for u
s
a
Regression slope of algorithm a (its respon-
siveness to user profile tendency)
b
a
Intercept of algorithm a (its baseline ten-
dency)
σ
2
a
Residual variance of algorithm a (its vari-
ability unexplained by user tendencies)

to model recommendation list distributions as a linear function of user profile distributions plus
random variance.
Figure shows a plate diagram of this model, and Table summarizes the key parameters; in
the following sections we explain each of the components and parameters in more detail.
4.3.1 User Profiles
For each user, we observe n
u
, the number of books they have rated with known author gender,
and y
u
, the number of female-authored books they have rated. From these obser vations, we es-
timate each user’s author-gender tendency θ
u
using a logit-normal model to address RQ. e
beta distribution is commonly used for modeling such tendencies, but the logit-normal has two
key advantages: it is more parsimonious when extended with a regression, as we can compute
regression coeficients in log-odds space, and it is substantially more computationally eficient to
sample. In early versions of this experiment we also found that it fit our data slightly better.
We use the following joint probability as our likelihood model:
y
u
∼ Binomial(n
u
, θ
u
)
logit(θ
u
) ∼ Normal(µ, σ)
logit(θ
u
) is the log odds of a known-gender book rated by user u being written by a female
author, and µ and σ are the mean and standard deviation of this user author-gender tendency.
Negative values indicate a tendency towards male authors, and positive values a tendency towards
female authors. θ
j
is the corresponding probability or proportion in the range [0, 1]. When sam-
pling from the fitted model, we produce a predicted θ
0
, n
0
, y
0
, and obser ved ratio y
0
/n
0
for each
sample in order to estimate the distribution of unseen user profiles.
We put vague priors on all parameters: σ, ν, γ ∼ Exponential(0.1), as they are positive, and
µ ∼ Normal(0, 10). ese priors provide difuse density across a wide range of plausible and
extreme values.
4.3.2 Recommendation Lists
For RQ and RQ, we model recommendation list gender distributions by extending our Bayesian
model to predict recommendation distributions with a linear regression based on each user’s smoothed
proportion and per-algorithm slope, intercept, and variance. e regression is in log-odds (logit)
space, and results in the following formula for estimating
¯
θ
ua
:
In early iterations of this work, we used broader priors; these vague priors are more in line with current STAN
recommendations (see https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations), and
do not afect inference conclusions.
¯y
ua
∼ Binomial(¯n
ua
)
logit(
¯
θ
ua
) = b
a
+ s
a
logit(θ
u
) +
ua
ua
∼ Normal(0, σ
a
)
e regression residual
ua
captures variance in the relationship between users’ and algorithms’
recommendation proportions beyond that intrinsic in the use of a binomial distribution, and giv-
ing it per-algorithm variance allows for some algorithms being more consistent in their output
than others. ¯n
ua
can difer between users and algorithms because the algorithms generate their
recommendations without regard for author gender, and we remove unknown-gender books from
the resulting lists for statistical analysis.
e result of our full model is that s
a
captures how much an algorithm’s output gender dis-
tribution varies with the input profile distribution, and σ
2
a
its variance independent of the input
distribution. b
a
expresses the algorithm’s typical gender balance when the user’s profile is evenly
balanced (since the log of even odds is zero).
In the full model, the recommendation lists can afect the inferred parameters for user pro-
files, because the model is expressed as a factored joint probability distribution that includes all
parameters. In practice, it is dificult to achieve separation, because we would need to either use
point estimates for user profile tendencies in the recommendation list analysis (losing the rich in-
formation the first inference obtains about the distributionof profile bias, including the uncertainty
in any particular user’s tendency), or import the entire set of samples from the profile phase into
the recommendation list phase (a process that is cost-prohibitive in current inference sotware).
4.3.3 Implementation
We fit and sample models with STAN [Carpenter et al., ], drawing , samples per model
( NUTS chains each performing warmup and sampling iterations). We report results
with the posterior predictive distributions of the parameters of interest, as estimated by the sam-
pling process.
5 Profile and Propagation Results
In this section we present the results of our statistical analysis of user profiles and recommenda-
tions. We begin with characterizing the profiles of our sample users, and then proceed to analyze
the resulting recommendations.
5.1 User Profile Characteristics
Under RQ, we want to understand the distribution of users’ author-gender tendencies, as repre-
sented by the proportion of known-gender books in each author’s profile that are written by female

Table : Summar y statistics for user profile gender distributions. µ is the posterior expected log
odds of P (female|known); σ
2
is the posterior variance of that log odds; and θ
0
is the posterior
expected proportion, or the mean P (female|known) the model expects for new, unseen users.
AZ BX-E BX-I GR-E GR-I
Obs. y/n . . . . .
Std. Dev. . . . . .
µ -. -. -. -. -.
% (-., -.) (-., -.) (-., -.) (-., -.) (-., -.)
σ . . . . .
E[θ
0
] (post.) . . . . .
Std. Dev. . . . . .
authors. e histograms in Fig. shows the distribution of observed author gender proportions,
while Table presents user profile summary statistics.
e Bayesian model from Section .. provides more rigorous, smoothed estimates of this
distribution. Table describes the numerical results of this inference. e key parameters are µ,
the average user’s author-gender tendency in log-odds; σ, the standard deviation of user author-
gender tendencies; and sampled θ values, the distribution of which describes the distribution of
user author-gender tendencies expressed as expected proportions.
Figure shows the densities of the author-gender tendency distribution, along with the den-
sities of projected and actual obser ved proportions. e ripples in predicted and obser ved pro-
portions are due to the commonality of -item user profiles, for which there are only possible
proportions; estimated tendency (θ) smooths them out. is smoothing, along with avoiding esti-
mated extreme biases based on limited data, are why we find it useful to estimate tendency instead
of directly computing statistics on obser ved proportions. e distribution of θ
0
— draws from the
posterior distribution of a hypothetical new user — describes what the model has inferred about
the distribution of user profile gender balances from the data it was provided. In the Amazon and
BookCrossing data, we see high frequency of all-male and all-female profiles; as can be seen from
the combination of smoothed tendency distribution and how it is reflected in predicted y/n distri-
butions, this naturally arises from the right skew in the user tendency distribution combined with
small profile sizes — an all-male profile is not just common in the data, but in the fitted model.
Comparing the obser ved and predicted y/n values in Fig. provides a graphical assessment
of model fit. e predicted values are samples of the obser vable gender balances that arise from θ
0
samples; under a well-fitting model, the distribution of these hypothetical users should be close to
the distribution of observed users. To support direct comparison of the densities of observations
and predictions, we resampled obser ved proportions with replacement to yield , obser va-
tions. While there is some mild divergence in the obser ved and predicted distributions of high-
female authors on the GoodReads data set, the models overall indicate good fit, and the means of
smoothed, predicted, and obser ved proportions are all very close.

Table : Recommendation coverage and diversity statistics (implicit).
AZ BX GR
Recs Dist. % Dist Recs Dist. % Dist Recs Dist. % Dist
ALS , , .% , , .% , , .%
BPR , , .% , , .% , , .%
II , , .% , , .% , , .%
II , , .% , , .% , , .%
Table : Recommendation coverage and diversity statistics (explicit).
AZ BX GR
Recs Dist. % Dist Recs Dist. % Dist Recs Dist. % Dist
ALS , , .% , .% — — —
II , , .% , , .% , , .%
UU , , .% , , .% , , .%
Takeaway RQ2
We obser ve a population tendency to rate male authors more frequently than female authors
in all data sets (µ < 0), but to rate female authors more frequently than they would be rated
were users drawing books uniformly at random from the available set (observed by compar-
ing E[θ
0
] to each data set’s fraction of female-authored books in Table ). e average user
author-gender tendency is slightly closer to an even balance than the set of rated books. We
also found substantial variance between users about their estimated tendencies (s.d. of pre-
dicted θ exceeds .; inferred σ > 1; both even-odds and book population proportions are
within one s.d. of estimated means). is means that some users are estimated to strongly
favor female authored books, even if these users are outnumbered by those that primarily
read male-authored books.
5.2 Recommendation List Distributions
Our first step in understanding how collaborative filtering algorithms respond to this data bias is
to examine the distribution of recommender list tendencies (RQ). As described in ., we pro-
duced recommendations from each algorithm. Tables and show the basic coverage statis-
tics of these algorithms. Users for which an algorithm could not produce recommendations are
rare. We also computed the extent to which algorithms recommend diferent items to diferent
users; “% Dist.” is the percentage of all recommendations that were distinct items. Algorithms
that repeatedly recommend the same items will be consistent in the gender distributions of their
recommendations. ALS on BX-E did not personalize at all, so we omit it from analysis.
Table provides the mean tendency for recommendation lists produced by each of our algo-
rithms, plus the tendency of Most Popular and Highest Average Rating recommenders. ese av-

Table : Mean / SD of rec. list female author proportions.
AZ BX GR
Popular . . .
Avg. Rating . . .
Implicit
ALS . / . . / . . / .
BPR . / . . / . . / .
II . / . . / . . / .
UU . / . . / . . / .
Explicit
ALS . / . . / . —
II . / . . / . . / .
UU . / . . / . . / .
erages are in line with the user profile averages shown in Table .
Figures and show the density of recommendation list proportions, again showing the
smoothed proportions with observed and predicted proportions for assessing model fit. e model
fits quite well for explicit-feedback recommenders; some recommender and data set combina-
tions on implicit-feedback, however, show significant efects that the model is not yet able to ac-
count for (as evidenced by the gaps between predicted and obser ved proportions). In particular,
all algorithms on Amazon have curves not captured in the predicted distribution, and Item-Item
on both BookCrossing and GoodReads exhibits a peak at about . that is not captured in the
model. e result is that our model likely underestimates the extent to which these algorithms
favor male-authored books. BPR on GoodReads favors both extreme-male and extreme-female
distributions, as evidenced by the two peaks in its distribution. Identifying these efects and ac-
counting for them in the model is let for future improvements of our experimental methodology;
the quality of fit in these charts does afect our confidence in the inferences in the next section.
e model predicts the implicit ALS algorithm’s distribution relatively well, and the distribution
shape is comparable to that of the input user profiles for each data set (compare with Fig. ).
Explicit feedback algorithms in the majority of cases cases had highly concentrated distribu-
tions of smoothed balances, and low variance in obser ved balances. We discuss the diferences
between implicit and explicit response further in Sections . and .
Takeaway RQ3
Recommendation list average balances are comparable to user profile average balances, but
otherwise there are notable diferences in the distribution of balances. e Implicit ALS al-
gorithm shows the most congruence between the distribution of recommendation list bal-
ances and user profile balances. BPR in particular has notable concentrations that decrease
recommendation diversity with respect to user profile diversity, and reflect a pattern not yet
captured in our model. Further research is needed to better understand what drives the dis-
tributions we observe and how to model the makeup of recommendation lists.

5.3 From Profiles to Recommendations
Our extended Bayesian model (Section ..) allows us to address RQ: the extent to which our
algorithms propagate individual users’ tendencies into their recommendations (RQ).
Figures – show the posterior predictive and observed densities of recommender author-
gender tendencies, and Figures – show scatter plots of obser ved recommendation propor-
tions against user profile proportions with regression curves (regression lines in log-odds space
projected into probability space). Figure shows the slope and intercept parameters with %
credible intervals.
In implicit-feedback mode, most algorithms are quite responsive to user profile balances, with
slopes greater than .. e GoodReads data set seems to exhibit the best fit in Fig. , and shows
the most direct reflection of user profiles into recommendation lists; it is also the densest, with
users tending to have more ratings in their profiles, giving the recommender algorithms more
to work with for producing accurate recommendations (see Fig. ) and estimating users’ profile
tendencies. e ALS algorithm has regression parameters quite close to perfect propagation for
all data sets, but especially GoodReads and Amazon (see Fig. ). Explicit-feedback mode shows
less responsiveness and stronger skews: all slopes are relatively small, and intercepts are negative
(meaning a user with an evenly-balanced input profile will receive recommendations that have
more men than women).
Takeaway RQ4
Implicit-feedback algorithms tend to reflect a user’s profile gender balance in their recom-
mendation lists. e strength and reliability of this propagation varies, but all data sets and
implicit-feedback algorithms exhibit a clear linear trend. It is most pronounced in GoodReads,
which has the most data for training; the implicit ALS algorithm is nearly a perfect line, and
BPR amplifies user’s tendencies towards female authors into their recommendation lists.
Explicit-feedback algorithms are much less responsive to their users’ input profiles, likely due
to the fact that they rely on rating values, not the mere presence of a book.
6 Forced-Balance Recommendation
So far we have sought to measure, without intervention, the distribution of author genders of
books recommended to users. is approach is quite reasonable given that neither past work,
nor the analysis presented here, is suficient to inform what recommendations should look like.
Individual recommender systems professionals may, through other data, analysis, or philosophy,
come to a conclusion about how they want their recommendation algorithms to behave.
In this section we address RQ with a suite of forced-balance recommenders that attempt to con-
strain the distribution in recommender output without substantially impacting recommendation
quality. We consider very simple algorithms for understanding this tradeof; the behavior of more
sophisticated approaches such as calibration [Steck, ] or independence [Kamishima et al.,
] are let for future work. As there is no general definition of “best tradeof ” between quality
and gender distribution, nor clear consensus about exactly what to target in the first place, such

an analysis would be premature. Instead we seek to provide lower-limits to what can be expected
from these type of tradeofs with simple approaches. is analysis ser ves as a starting point for
future explorations into recommender systems that deliberately pursue targeted changes in rec-
ommendation properties.
We consider three force-balance recommenders:
• single-pass force-balance (SingleEQ)
• multi-pass force-balance (GreedyEQ)
• multi-pass calibrate (GreedyReflect)
All three algorithms are implemented as a post-processor that can be applied to any base rec-
ommendation technique, much like Ziegler et al.’s topic diversification [Ziegler et al., ]. is
means the primar y input to these algorithms is an existing ranking of the item set. Oten this in-
put will be a list of items sorted by the prediction or ranking scores generated by a base algorithm.
We operated the algorithms with a ranking over the entire item set as their input; for eficiency,
truncated rankings could be used. All three algorithms start from the top of the input ranking and
preserve it to varying degrees; they thus implicitly balance recommendation accuracy with gender
representation by perturbing an accuracy-optimized ranking only insofar as adjustments are nec-
essary to achieve their gender balance targets. Alongside the input ranking, all three force-balance
algorithms also take the gender labels for each book and a target size for the list. e target size
parameter allows for the common use of a recommendation algorithm in assembling a top-N list
of fixed size.
e goal of the first two algorithms is to recommend approximately equal numbers of male-
and female-authored books. In SingleEQ (Algorithm ) this is accomplished in a single pass of
the input recommendation list e algorithm is quite simple: for each item in the input base-
algorithm ranking (in order) the algorithm either accepts the item (adding it to the output list of
items) or reject it. Items are rejected if they would make the gender balance of the current output
list further from our target. So while the current output list has more female authored books than
male authored books it will reject female authored item recommendations
. Likewise, if the cur-
rent output list has more male authored books, then it will reject additional male authored books.
Note that books with unknown or unlinked gender are always recommended as they will have no
efect on the known-gender gender balance of the generated recommendations. e algorithm
proceeds in this manner, accepting and rejecting items from the base recommendation list, until
the target recommendation size is reached.
Both GreedyEQ and GreedyReflect share the same general algorithm (Algorithm ), and are
structured more like a traditional greedy optimizer. e only diference is that GreedyEQ seeks a
target balance of . while GreedyReflect targets the balance observed in each user’s ratings.
e GreedyEQ algorithm proceeds iteratively, at each step selecting the next item to add to
it’s output list. Each step of the algorithm loops over the base recommendations selecting the
top ranked item satisfying two constraints: ) the item is not already in the output list, and ) the
is does not accommodate authors with non-binar y gender identities. Our goal here is examine the behavior of
simple mechanisms supported by available data.

Algorithm 1: Single-pass Equalize (SingleEQ)
Data: ranked list L, target length n, attribute G : L → m, f, ⊥
Result: ranked list L
0
L
0
← empty list;
n
f
, n
m
← 0;
for i ∈ L do
if G(i) = ⊥ then
add i to L
0
;
else if G(i) = f ∧ n
f
≤ n
m
then
add i to L
0
;
n
f
← n
f
+ 1;
else if G(i) = m ∧ n
m
≤ n
f
then
add i to L
0
;
n
m
← n
m
+ 1;
end
if |L
0
| ≥ n then
break;
end
end
item would not lead to a worse gender imbalance. To determine if the item would lead to a worse
imbalance we begin by estimating the current balance of the output list. If our current balance
is more female heavy than our target balance we only add male-authored books. If our current
balance is more male heavy than our target balance we only add female authored books. If our
current balance is equal to our target balance we are willing to accept any book. As before, unkown
and unlinked authors are recommended as they are reached by this algorithm.
is iterative process allows GreedyEQ to pick up items that were skipped in a past step, should
the current gender balance of the output list allow them, leading to better recommendations. e
cost for this improvement is taking many more passes over the item set, possibly increasing rec-
ommendation time, especially for large target recommendation sizes.
e third and final reranker, multi-pass calibrate (GreedyReflect), is based on Steck ’s concept
of calibration [Steck, ]. Rather than targeting a gender balance of ., it targets the balance
observed in the user’s ratings.
All three algorithms are designed to ensure that the output list will be at most one male- or
female- authored book above (or below) the target gender balance, while being as close to the un-
derlying ranking as possible. Due to the iterative nature of the algorithm, this will also hold true of
every prefix of the output list, ensuring that the output list isn’t separated into a clear "male half "
and "female half " but instead has genders well-mixed throughout the list.
We repeated our evaluation from Section .. with the reranking algorithms to measure their
accuracy loss. Figure shows the results of this experiment, and Table shows the relative loss
of balancing each algorithm for each data set. Most penalties are quite small at just a few percent;

Algorithm 2: Greedy Rebalance
Data: ranked list L, target length n, attribute G : L → m, f, ⊥, target balance p
Result: ranked list L
0
L
0
← empty list;
n
f
, n
m
← 0;
while |L
0
| < n do
p
0
← n
f
/(n
f
+ n
m
);
for i ∈ L \ L
0
do
if G(i) = ⊥ then
add i to L
0
;
break;
else if G(i) = f ∧ p
0
≤ p then
add i to L
0
;
n
f
← n
f
+ 1;
break;
else if G(i) = m ∧ p
0
≥ p then
add i to L
0
;
n
m
← n
m
+ 1;
break;
else // out of options, end early
return L
0
;
end
end
end

GreedyEQ GreedyReflect SingleEQ
DataSet Implicit Algorithm
AZ False ALS .% -.% -.%
II .% -.% .%
UU -.% .% -.%
True ALS .% .% .%
BPR .% -.% .%
II .% .% .%
UU .% .% .%
BX False ALS .% -.% .%
II .% -.% .%
UU .% -.% -.%
True ALS .% .% .%
BPR .% .% .%
II .% .% .%
UU .% .% .%
GR False II .% -.% .%
UU .% .% .%
True ALS .% .% .%
BPR .% .% .%
II .% .% .%
UU .% .% .%
Table : Accuracy loss for balancing genders.
the largest are (item-item on BX-E, user-user on GR-E) are on algorithms that do not perform well
to begin with. In some cases the calibrated balancing even improves the recommender’s accuracy
slightly.
As expected, the multi-pass GreedyEQ algorithm generally outperforms SingleEQ. GreedyRe-
flect, matching the user’s profile balance instead of an arbitrar y target of ., usually performs the
best.
Takeaway RQ5
We find, therefore, that it is possible to adjust the recommendation output balance with very
simple approaches without substantial loss in accuracy. It also seems there is much room
for more nuanced or refined adjustment. Again, we do not present these as particularly ad-
vanced approaches, but to establish an estimate of what should be possible. ese results are
consistent with those of Geyik and Kenthapadi [], where re-ranking techniques improved
representation in job candidate search results without any harm to user engagement.
7 Discussion
We have obser ved the distribution of book author genders across the book recommendation pipeline
(Fig. ). Encouragingly for our societal goal of ensuring good representation in book authorship,
representation of women seems to be higher in later stages of the pipeline: women write a greater
share of rated books than cataloged books, and their books have more user interactions on aver-
age.
ere is substantial variance between users in the gender balance of their historical book in-
teractions, but on average, their profiles have better female author representation than the under-
lying book corpus does.
ese author tendencies are then reflected into recommendations, particularly by implicit-
feedback recommenders. Implicit-feedback recommendations were more reflective both of the
overall distribution of user profile tendencies and each individual user’s gender balance than explicit-
feedback recommenders; this is likely because the explicit-feedback recommendations are pri-
marily driven by the ratings that users give to books, rather than the presence of the book in
the user’s recommendation list. It is not surprising that the composition of a user’s profile has a
greater impact on algorithms that use the profile composition than it does on algorithms that use
associated rating values, but it is useful to empirically document this diference in efect because
it is dificult to predict a priori how algorithms will interact with particular socially-salient fea-
tures of their input data that afect either its presence or its value. Perhaps in the future the social
structure of recommendation data and consumption patterns will be suficiently well-understood
to make such predictions, but the current state of the art does not support them.
Recommender propagation of user profile balance seems to be both a blessing and a curse. On
the one hand, it is encouraging that the algorithms are capturing and reflecting patterns in users’
book consumption, whether those patterns are an actual gender preference or another preference
that corresponds with author gender. Further, if a user wants to read books by underrepresented
authors, and has found a number to put in their profile, a well-tuned collaborative filter may help
them find more (although we need to empirically study recommender response to other axes of
under-representation; we cannot assume that gender results will apply to e.g. ethnicity). On the
other hand, if a user is reading predominantly majority authors, the collaborative filter will prob-
ably reinforce that tendency as well.
It is not yet clear what to do about this. e methods and results we have presented here are
focused on describing what recommender system inputs and outputs look like, but we are also in-
terested in how to deploy information access technologies to further social objectives. In addition
to the roles Abebe et al. [] identify for computing in promoting social change, we think infor-
mation access is a domain in which computing can be applied to directly catalyze positive social
outcomes, particularly by promoting the work of content creators who have historically been over-
looked. We have tested a few simple techniques for forcing particular representational goals, and
found that they have little negative impact on recommendation accuracy, but whether and how to
deploy such techniques is very much an open question.
In candidate sourcing and recruiting as a part of the hiring pipeline [Geyik and Kenthapadi,
], it seems clearly appropriate to deploy interventions to ensure representative search results.
At least in the U.S. context, anti-discrimination law means that a recruiting platform’s users are
already legally required to ensure some forms of representativeness. In other settings, however, it
is less clear. Overriding the system’s modeling of user preference to achieve the system designer’s
social goals may violate what agency users retain in their use of the recommender system [Ek-
strand and Willemsen, ]. Leaving the system to propagate what patterns it will, however, may
perpetuate inequities and deny content creators equal access to the creative marketplace (e.g. the
goals outlined by Mehrotra et al. []). e space of available inter ventions is not limited to
either inaction or modifying the primary recommender, however; in some platforms, it may be
feasible to deploy social nudges through additional recommendation experiences, such as adding
a “New Authors You Might Love” feature that selects books for, among other things, author voices
that are underrepresented in the corpus as a whole or in the individual user’s historical activity.
Regardless of the appropriate solution, it is important to first understand what a system’s data
and behavior currently look like. We have presented results, reusable experimental methods, and
a new composite data set for conducting such measurements of recommender systems. e next
steps will be an ongoing discussion in the community of researchers and practitioners.
7.1 Limitations of Data and Methods
Our data and approach has a number of limitations that are important to note. First, book rating
data is extremely sparse, and the BookCrossing data set is small, providing a limited picture of
users’ reading histories and reducing the performance of some algorithms. In particular, the high
sparsity of the data set caused the MF algorithm to perform particularly poorly on ofline accuracy
metrics, so these findings may not be representative of its behavior in the wild; future work will
need to test them across a range of recommender efectiveness levels and stages of system cold-
start.
Second, our data and statistical methods only account for binar y gender identities. While the
MARC Authority Format supports flexible gender identity records (including multiple possibly-
overlapping identities over the course of an author’s life and nonbinar y identities from an open
vocabular y), VIAF does not seem to use this flexibility.
ird, we test a limited set of collaborative filtering algorithms. While we have chosen algo-
rithms with an eye for diverse behaviors and global popularity, we must acknowledge that our
selection of algorithms is small in the face of algorithm diversity in the field. While our ultimate
goal is to understand general trends, we acknowledge that our study does not evaluate enough
algorithms to make claims about the entire field.
We consider it valuable to make forward progress in understanding the interaction of informa-
tion systems with social concerns using the data we have available, even if that data has significant
known weaknesses. We must, however, be reflective and forthright about the limitations of the
data, methods, and resulting findings, and seek to improve them in order to develop a better un-
derstanding of the human impact of computing systems. Our experimental design can be readily
extended to accommodate richer or higher-quality data sources and additional algorithms, and
the code we provide for our experiments will facilitate such improvements. We have tested this
reproducibility by re-running the experiments in the course of writing and revising this paper. Ul-
timately we see this as the first step in untangling a broader issue; we are actively exploring many
extensions and improvements to this work.
7.2 Limitations of Current Results
Beyond the general limitations of our data and methods, there is much that our results here have
let unexplored. We have only looked at uncontrolled distributions and correlations of author gen-
ders; we have not looked at any subdivisions, such as book genres. Author gender distributions
may difer between genres or topics, and some of the efects we observe may be the result of user
preferences for genres, topics, or other characteristics that happen to correlate with author gender
for various reasons.
We believe obser vational, correlational studies such as the one we have presented have signifi-
cant value in identifying the presence of potential efects. ey are insuficient to establish causal-
ity, and they do not tell us why the efects are happening, but they provide insight into where to go
looking to find the causal drivers of human and algorithmic behavior.
We hope that future work will uncover the factors that drive the relationships we have obser ved
and yield deeper insight into both user behavior and the patterns that recommender systems can
capture and reflect. We plan, of course, to carry out some of that work ourselves, but there is a
great deal of space to explore. One particularly important next step is to adapt fairness constructs
based on exposure [Diaz et al., ] or attention [Biega et al., ] to this problem setting; these
account for rank position in addition to presence in a recommendation list, connect fair exposure
to relevance, and are also more amenable to assessing fairness with respect to non-binar y author
attributes [Raj et al., ].
8 Conclusion and e Road Ahead
We have conducted an initial inquir y into the response of collaborative filtering book recommenders
to gender distributions in the user preference data on which they are trained. Collaborative filter-
ing algorithms trained on binar y user-book interactions (“implicit feedback ”) tended to reflect the
historical gender balance of users’ reading patterns into their recommendations.
is paper is a first step in a much larger project to understand the ways in which recommen-
dation algorithms interact with potentially discriminatory biases, and general behavior of recom-
mendation technology with respect to various social issues. ere are many future steps we see
for advancing this agenda:
• Obtaining higher-quality data for measuring distributions of interest in recommender in-
puts and outputs. is includes obtaining data on non-binar y gender identities and adopt-
ing statistical methods that can account for them.
• Examining other content creator features, such as ethnicity, in recommendation applica-
tions.
• Extending to additional algorithm families, such as content-based filters.
• Studying other domains and applications, such as movies, research literature, and social
media.
• Develop more advanced algorithms that interact with various user or item characteristics
of social concern; these could be developed to reflect organizational or societal goals or to
help users further their individual goals [Ekstrand and Willemsen, ].
• Study the efect of existing refinements, such as diversification [Willemsen et al., , Ziegler
et al., ], on recommendation distributions.
We hope to see more work in the coming years to better understand ways in which recom-
mender systems respond to and influence their sociotechnical contexts.
Acknowledgements
We thank Mucun Tian, Mohammed R. Imran Kazi, and Hoda Mehrpouyan for their contribu-
tions to the conference paper on which this work builds, and the People and Information Research
Team (PIReT) for their support and feedback to help refine this research agenda. Computation
performed on the R cluster [Boise State Research Computing Department, ].
References
R. Abebe, S. Barocas, J. Kleinberg, K. Levy, M. Raghavan, and D. G. Robinson. Roles for computing
in social change. In Proceedings of the Conference on Fairness, Accountability, and Transparency,
FAT* ’, pages –, New York, NY, USA, Jan. . Association for Computing Machin-
ery. ISBN . doi: ./.. URL https://doi.org/10.1145/
3351095.3372871.
G. Adomavicius and A. Tuzhilin. Toward the next generation of recommender systems: a sur-
vey of the state-of-the-art and possible extensions. IEEE Transactions on Knowledge and Data
Engineering, ():–, . ISSN -. doi: ./TKDE... URL http:
//dx.doi.org/10.1109/TKDE.2005.99.
M. Ali, P. Sapiezynski, M. Bogen, A. Korolova, A. Mislove, and A. Rieke. Discrimination through
optimization: How facebook ’s ad delivery can lead to biased outcomes. Proc. ACM Hum.-Comput.
Interact., (CSCW):–, Nov. . doi: ./. URL https://doi.org/10.1145/
3359301.
A. Bellogin, P. Castells, and I. Cantador. Precision-oriented evaluation of recommender systems:
An algorithmic comparison. In Proceedings of the Fith ACM Conference on Recommender Systems,
RecSys ’, page –, New York, NY, USA, . ACM. ISBN . doi: ./
.. URL http://doi.acm.org/10.1145/2043932.2043996.
A. Beutel, E. H. Chi, C. Goodrow, J. Chen, T. Doshi, H. Qian, L. Wei, Y. Wu, L. Heldt, Z. Zhao,
and L. Hong. Fairness in recommendation ranking through pair wise comparisons. In Proceed-
ings of the th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM
Press, . ISBN . doi: ./.. URL http://dl.acm.org/
citation.cfm?doid=3292500.3330745.
A. J. Biega, K. P. Gummadi, and G. Weikum. Equity of attention: Amortizing individual fairness
in rankings. In est InternationalACMSIGIR Conferenceon Research & Development in Information
Retrieval, pages –. ACM, June . ISBN . doi: ./..
URL https://dl.acm.org/citation.cfm?doid=3209978.3210063.
A. Billey, M. Haugen, J. Hostage, N. Sack, and A. L. Schif. Report of the PCC ad hoc task
group on gender in name authority records. Technical report, Program for Cooperative
Cataloging, Oct. . URL https://www.loc.gov/aba/pcc/documents/Gender_375%
20field_RecommendationReport.pdf.
Boise State Research Computing Department. R: Dell HPC intel ev (high performance com-
puting cluster), . URL http://dx.doi.org/10.18122/B2S41H.
T. Bolukbasi, K.-W. Chang, J. Zou, V. Saligrama, and A. Kalai. Man is to computer programmer as
woman is to homemaker? debiasing word embeddings. In D. D. Lee and M. Sugiyama and U.
V. Luxburg and I. Guyon and R. Garnett, editor, Advances in Neural Information Processing Systems
(NIPS ). Curran Associates, Inc., July . URL http://papers.nips.cc/paper/
6227-man-is-to-computer-programmer-as-woman-is-to-homemaker-debiasing-word-embeddings.
D. Bucur. Gender homophily in online book networks. Information sciences, :–, May
. ISSN -. doi: ./j.ins.... URL http://www.sciencedirect.
com/science/article/pii/S0020025519300040.
J. Buolamwini and T. Gebru. Gender shades: Intersectional accuracy disparities in commer-
cial gender classification. In Proceedings of the st Conference on Fairness, Accountability, and Trans-
parency, volume of Proceedings of Machine Learning Research, page –. PMLR, . URL
http://proceedings.mlr.press/v81/buolamwini18a.html.
R. Burke. Multisided fairness for recommendation. coRR, July . URL http://arxiv.org/
abs/1707.00093.
R. Burke, N. Sonboli, and A. Ordonez-Gauger. Balanced neighborhoods for multi-sided fairness
in recommendation. In S. A. Friedler and C. Wilson, editors, Proceedings of the st Conference
on Fairness, Accountability and Transparency, volume of Proceedings of Machine Learning Research,
pages –, New York, NY, USA, . PMLR. URL http://proceedings.mlr.press/
v81/burke18a.html.
B. Carpenter, A. Gelman, M. Hofman, D. Lee, B. Goodrich, M. Betancourt, M. Brubaker, J. Guo,
P. Li, and A. Riddell. Stan: A probabilistic programming language. Journal of Statistical Sotware,
():–, . ISSN -. doi: ./jss.v.i. URL https://www.jstatsoft.
org/v076/i01.
O. Celma. Music Recommendation and Discovery: e Long Tail, Long Fail, and Long Play in
the Digital Music Space. Springer, Berlin, Heidelberg, . ISBN .
doi: ./- - - - . URL https://link.springer.com/book/10.1007%
2F978-3-642-13287-2.
S. Channamsetty and M. D. Ekstrand. Recommender response to diversity and popularity bias in
user profiles. In Proceedingsof the th Florida Artificial IntelligenceResearch Society Conference. AAAI
Press, May . URL https://aaai.org/ocs/index.php/FLAIRS/FLAIRS17/paper/
view/15524/15019.
D. Cosley, D. Frankowski, L. Ter veen, and J. Riedl. SuggestBot: Using intelligent task routing to
help people find work in wikipedia. In Proceedings of the th International Conference on Intelligent
User Interfaces, IUI ’, pages –, New York, NY, USA, Jan. . Association for Computing
Machinery. ISBN . doi: ./.. URL https://doi.org/10.
1145/1216295.1216309.
M. Deshpande and G. Karypis. Item-based Top-N recommendation algorithms. ACM Transactions
on Information Systems, ():–, Jan. . ISSN -. doi: ./..
URL https://doi.org/10.1145/963770.963776.
F. Diaz, B. Mitra, M. D. Ekstrand, A. J. Biega, and B. Carterette. Evaluating stochastic rankings
with expected exposure. In Proceedings of the th ACM International Conference on Information and
Knowledge Management. ACM, Oct. . doi: ./.. URL http://arxiv.
org/abs/2004.13157.
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel. Fairness through awareness. In Pro-
ceedings of the rd Innovations in eoretical Computer Science Conference, ITCS ’, page –,
New York, NY, USA, . ACM. ISBN . doi: ./.. URL
http://doi.acm.org/10.1145/2090236.2090255.
M. Ekstrand, J. Riedl, and J. A. Konstan. Collaborative filtering recommender systems. Foun-
dations and Trends® in Human-Computer Interaction, ():–, . ISSN -. doi:
./. URL http://dx.doi.org/10.1561/1100000009.
M. D. Ekstrand. LensKit for Python: Next-Generation sotware for recommender system exper-
iments. In Proceedings of the th ACM International Conference on Information and Knowledge Man-
agement, . doi: ./.. URL http://dx.doi.org/10.1145/3340531.
3412778.
M. D. Ekstrand and J. A. Konstan. Recommender systems notation. Technical Report , Boise
State University, . URL https://scholarworks.boisestate.edu/cs_facpubs/
177/.
M. D. Ekstrand and M. C. Willemsen. Behaviorism is not enough: Better recommendations
through listening to users. In Proceedings of the th ACM Conference on Recommender Systems,
RecSys ’, page –, New York, NY, USA, . ACM. ISBN . doi: ./
.. URL http://doi.acm.org/10.1145/2959100.2959179.
M. D. Ekstrand, M. Tian, I. M. Azpiazu, J. D. Ekstrand, O. Anuyah, D. McNeill, and M. S. Pera.
All the cool kids, how do they fit in?: Popularity and demographic biases in recommender eval-
uation and efectiveness. In S. A. Friedler and C. Wilson, editors, Proceedings of the Conference
on Fairness, Accountability, and Transparency (PMLR), volume of Proceedings of Machine Learning
Research, pages –, New York, NY, USA, Feb. . PMLR. URL http://proceedings.
mlr.press/v81/ekstrand18b.html.
D. Ensign, S. A. Friedler, S. Neville, C. Scheidegger, and S. Venkatasubramanian. Runaway feed-
back loops in predictive policing. In S. A. Friedler and C. Wilson, editors, Proceedings of the st
Conference on Fairness, Accountability and Transparency, volume of Proceedings of Machine Learning
Research, pages –, New York, NY, USA, . PMLR. URL http://proceedings.mlr.
press/v81/ensign18a.html.
A. Epps-Darling, R. T. Bouyer, and H. Cramer. Artist gender representation in music stream-
ing. In Proceedings of the st International Society for Music Information Retrieval Conference, page
–. ISMIR, Oct. . URL https://program.ismir2020.net/poster_2-11.html.
M. Feldman, S. A. Friedler, J. Moeller, C. Scheidegger, and S. Venkatasubramanian. Certifying
and removing disparate impact. In Proceedings of the th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining, pages –. ACM, Aug. . ISBN .
doi: ./.. URL http://dl.acm.org/citation.cfm?doid=2783258.
2783311.
S. A. Friedler, C. Scheidegger, and S. Venkatasubramanian. On the (im)possibility of fairness.
arXiv:. [cs, stat], Sept. . URL http://arxiv.org/abs/1609.07236.
B. Friedman and H. Nissenbaum. Bias in computer systems. ACM Transactions on Information and
System Security, ():–, July . ISSN -, -. doi: ./..
URL http://doi.acm.org/10.1145/230538.230561.
A. Gelman and F. Tuerlinckx. Type S error rates for classical and bayesian single and multi-
ple comparison procedures. Computational Statistics, ():–, . ISSN -.
doi: ./s. URL https://link.springer.com/article/10.1007/
s001800000040.
A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, and D. B. Rubin. Hierarchical mod-
els. In Bayesian Data Analysis, page –. CRC Press, rd edition, . ISBN .
S. C. Geyik and K. Kenthapadi. Building representative talent search
at LinkedIn. https://engineering.linkedin.com/blog/2018/
10/building-representative-talent-search-at-linkedin, Oct.
. URL https://engineering.linkedin.com/blog/2018/10/
building-representative-talent-search-at-linkedin. Accessed: --.
A. Gunawardana and G. Shani. Evaluating recommender systems. In Recommender Systems Hand-
book, pages –. Springer, Boston, MA, . ISBN , . doi:
./- - - - \_. URL https://link.springer.com/chapter/10.1007/
978-1-4899-7637-6_8.
F. Hamidi, M. K. Scheuerman, and S. M. Branham. Gender recognition or gender reduction-
ism?: e social implications of embedded gender recognition systems. In Proceedings of the
CHI Conference on Human Factors in Computing Systems, CHI ’, page . ACM, Apr. . ISBN
. doi: ./.. URL http://dl.acm.org/ft_gateway.cfm?
id=3173582&type=pdf.
A. Hannak, C. Wagner, D. Garcia, M. Strohmaier, and C. Wilson. Bias in online freelance mar-
ketplaces: Evidence from TaskRabbit. In Proceedings of the Workshop on Data and Algorithm Trans-
parency, . URL http://datworkshop.org/papers/dat16-final22.pdf.
F. M. Harper and J. A. Konstan. e MovieLens datasets: History and context. ACM Transactions
on Interactive Intelligent Systems, ()::–:, Dec. . ISSN -. doi: ./.
URL http://doi.acm.org/10.1145/2827872.
C. R. Harris, K. J. Millman, S. J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau,
E. Wieser, J. Taylor, S. Berg, N. J. Smith, R. Kern, M. Picus, S. Hoyer, M. H. van Kerkwijk,
M. Brett, A. Haldane, J. F. Del Río, M. Wiebe, P. Peterson, P. Gérard-Marchant, K. Shep-
pard, T. Reddy, W. Weckesser, H. Abbasi, C. Gohlke, and T. E. Oliphant. Array program-
ming with NumPy. Nature, ():–, Sept. . ISSN -, -. doi:
./s- - - . URL http://dx.doi.org/10.1038/s41586-020-2649-2.
J. Herlocker, J. A. Konstan, A. Borchers, and J. Riedl. An algorithmic framework for perform-
ing collaborative filtering. In Proceedings of the nd Annual International ACM SIGIR Conference
on Research and Development in Information Retrieval, pages –. ACM, . doi: ./
.. URL http://portal.acm.org/citation.cfm?id=312682&dl=GUIDE&
coll=GUIDE.
J. Herlocker, J. A. Konstan, L. Ter veen, and J. Riedl. Evaluating collaborative filtering recom-
mender systems. ACM Transactions on Information Systems, ():–, . ISSN -.
doi: ./.. URL http://portal.acm.org/citation.cfm?id=963772.
A. L. Hofmann. Data violence and how bad engineering
choices can damage society. https://medium.com/s/story/
data-violence-and-how-bad-engineering-choices-can-damage-society-39e44150e1d4,
Apr. . URL https://medium.com/s/story/data-violence-and-how-bad-engineering-choices-can-damage-society-39e44150e1d4.
Accessed: --.
K. Hosanagar, D. Fleder, D. Lee, and A. Buja. Will the global village fracture into tribes? rec-
ommender systems and their efects on consumer fragmentation. Management Science, ():
–, Nov. . ISSN -. doi: ./mnsc... URL https://doi.org/
10.1287/mnsc.2013.1808.
J. C. Hu. e over whelming gender bias in ’New York Times’ book reviews. https://psmag.com/
social-justice/gender-bias-in-book-reviews, Aug. . URL https://psmag.
com/social-justice/gender-bias-in-book-reviews. Accessed: --.
N. Hurley and M. Zhang. Novelty and diversity in Top-N recommendation – analysis and evalu-
ation. ACM Transactions on Internet Technology, ()::–:, Mar. . ISSN -. doi:
./.. URL http://doi.acm.org/10.1145/1944339.1944341.
J. Hutson, J. Tat, S. Barocas, and K. Levy. Debiasing desire: Addressing bias and discrimina-
tion on intimate platforms. Proceedings of the ACM on Human-Computer Interaction, (CSCW):
, Sept. . doi: ./. URL https://papers.ssrn.com/sol3/papers.cfm?
abstract_id=3244459.
D. Jannach, L. Lerche, I. Kamehkhosh, and M. Jugovac. What recommenders recom-
mend: An analysis of recommendation biases and possible countermeasures. User Mod-
eling and User-Adapted Interaction, ():–, July . ISSN -, -.
doi: ./s- - - . URL http://link.springer.com/article/10.1007/
s11257-015-9165-3.
T. Kamishima, S. Akaho, H. Asoh, and J. Sakuma. Recommendation independence. In S. A.
Friedler and C. Wilson, editors, ProceedingsofthestConferenceonFairness, AccountabilityandTrans-
parency, volume of Proceedings of Machine Learning Research, pages –, New York, NY,
USA, . PMLR. URL http://proceedings.mlr.press/v81/kamishima18a.html.
H. Kibirige, G. Lamp, J. Katins, A. O., gdowding, T. Funnell, matthias-k, J. Arnfred, F. Finker-
nagel, D. Blanchard, E. Chiang, S. Astanin, P. N. Kishimoto, stonebig, E. Sheehan, R. Gib-
boni, B. Willers, Pavel, Y. Halchenko, smutch, zachcp, J. Collins, R. K. Min, B. King, D. Brian,
D. Arora, D. Brown, D. Becker, B. Koopman, and Anthony. hask/plotnine: v.., Aug. .
URL https://zenodo.org/record/3373970.
B. P. Knijnenburg, M. C. Willemsen, Z. Gantner, H. Soncu, and C. Newell. Explaining the user
experience of recommender systems. User Modeling and User-Adapted Interaction, ():–,
Oct. . ISSN -. doi: ./s- - - . URL https://doi.org/10.
1007/s11257-011-9118-4.
R. Kuprieiev, D. Petrov, R. Valles, P. Redzyński, C. da Costa-Luis, A. Schepanovski, I. Shcheklein,
S. Pachhai, J. Orpinel, F. Santos, A. Sharma, Zhanibek, D. Hodovic, Earl, A. Grigorev, N. Dash,
G. Vyshnya, maykulkarni, Vera, M. Hora, xliiv, P. Rowlands, W. Baranowski, S. Mangal, and
C. Wolf. DVC: Data version control - git for data & models, May . URL https://zenodo.
org/record/3813759.
N. Lathia, S. Hailes, L. Capra, and X. Amatriain. Temporal diversity in recommender sys-
tems. In Proceeding of the rd International ACM SIGIR Conference on Research and Development
in Information Retrieval, SIGIR ’, pages –. ACM, . ISBN . doi:
./.. URL http://portal.acm.org/citation.cfm?id=1835486.
Library of Congress. MARC standards. Technical report, . URL https://www.loc.gov/
marc/.
K. Lum and W. Isaac. To predict and serve? Significance, ():–, Oct. . ISSN -.
doi: ./j.- ...x. URL http://onlinelibrary.wiley.com/doi/10.
1111/j.1740-9713.2016.00960.x/abstract.
G. Magno, C. S. Araújo, W. Meira, Jr., and V. Almeida. Stereotypes in search engine results: Under-
standing the role of local and global factors. In Proceedings of the Workshop on Data and Algorithm
Transparency, Sept. . URL http://arxiv.org/abs/1609.05413.
J. McAuley, C. Targett, Q. Shi, and A. van den Hengel. Image-Based recommendations on styles
and substitutes. In Proceedings of the th International ACM SIGIR Conference on Research and
Development in Information Retrieval, SIGIR ’, pages –, New York, NY, USA, . ACM.
ISBN . doi: ./.. URL http://doi.acm.org/10.1145/
2766462.2767755.
W. McKinney and Others. Data structures for statistical computing in python. In Proceedings of
the th Python in Science Conference, volume , pages –, . URL http://conference.
scipy.org/proceedings/scipy2010/pdfs/mckinney.pdf.
R. Mehrotra, J. McInerney, H. Bouchard, M. Lalmas, and F. Diaz. Towards a fair marketplace:
Counterfactual evaluation of the trade-of between relevance, fairness & satisfaction in rec-
ommendation systems. In Proceedings of the th ACM International Conference on Information and
Knowledge Management, CIKM ’, pages –. ACM, Oct. . ISBN .
doi: ./.. URL http://dl.acm.org/ft_gateway.cfm?id=3272027&
type=pdf.
A. Mislove, S. Lehmann, Y.-Y. Ahn, J.-P. Onnela, and J. N. Rosenquist. Understanding the demo-
graphics of twitter users. In Proceedings of the th International AAAI Conference on Weblogs and So-
cial Media, . URL https://www.aaai.org/ocs/index.php/ICWSM/ICWSM11/paper/
view/2816.
T. T. Nguyen, P.-M. Hui, F. M. Harper, L. Ter veen, and J. A. Konstan. Exploring the filter bubble:
e efect of using recommender systems on content diversity. In Proceedings of the rd Interna-
tional Conference on World Wide Web, WWW ’, page –, New York, NY, USA, . ACM.
ISBN . doi: ./.. URL http://doi.acm.org/10.1145/
2566486.2568012.
V. Pajović and K. Vyskocil. CWIL A count methods and results. https://cwila.
com/2015-cwila-count-methods-results/, Oct. . URL https://cwila.com/
2015-cwila-count-methods-results/. Accessed: --.
E. Pariser. e Filter Bubble: How the New Personalized Web Is Changing What We Read and How We
ink. Penguin, May . ISBN .
I. Pilászy, D. Zibriczky, and D. Tikk. Fast ALS-based matrix factorization for explicit and implicit
feedback datasets. In Proceedings of the Fourth ACM Conference on Recommender Systems, RecSys
’, page –, New York, NY, USA, . ACM. ISBN . doi: ./.
. URL http://doi.acm.org/10.1145/1864708.1864726.
A. Raj, C. Wood, A. Montoly, and M. D. Ekstrand. Comparing fair ranking metrics. coRR, Sept.
. URL http://arxiv.org/abs/2009.01311.
J. Reback, W. McKinney, jbrockmendel, J. Van den Bossche, T. Augspurger, P. Cloud, gfyoung,
Sinhrks, A. Klein, M. Roeschke, S. Hawkins, J. Tratner, C. She, W. Ayd, T. Petersen, M. Garcia,
J. Schendel, A. Hayden, MomIsBestFriend, V. Jancauskas, P. Battiston, S. Seabold, chris-b, h-
vetinari, S. Hoyer, W. Overmeire, alimcmaster, K. Dong, C. Whelan, and M. Mehyar. pandas-
dev/pandas: Pandas .., Mar. . URL https://zenodo.org/record/3715232.
S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-ieme. BPR: Bayesian personalized
ranking from implicit feedback. In Proceedings of the Twenty-Fith Conference on Uncertainty in Ar-
tificial Intelligence, UAI ’, page –, Arlington, Virginia, United States, . AUAI Press.
ISBN . URL http://dl.acm.org/citation.cfm?id=1795114.1795167.
P. Resnick. Beyond bowling together: Sociotechnical capital. HCI in the New Millennium, :–
, . URL https://mccti.hugoramos.eu/Redes_Sociais_Online/TEXTOS_
AULAS/TEXTO_AULA_07_Beyond%20Bowling%20Together%20SocioTechnical%
20Capital_Resnick.pdf.
C. Riederer and A. Chaintreau. e price of fairness in location based advertising. Fairness, Ac-
countability and Transparency in Recommender Systems, Aug. . URL http://scholarworks.
boisestate.edu/fatrec/2017/1/5.
A. Rosenblat and L. Stark. Algorithmic labor and information asymmetries: A case study of uber’s
drivers. International Journal of Communication, ():, July . ISSN -. URL http:
//ijoc.org/index.php/ijoc/article/view/4892/1739.
P. Sapiezynski, W. Zeng, R. E Robertson, A. Mislove, and C. Wilson. Quantifying the impact of
user attentionon fair group representation in ranked lists. In Companion Proceedings of e
World Wide Web Conference, WWW ’, pages –, New York, NY, USA, May . Association
for Computing Machiner y. ISBN . doi: ./.. URL https:
//doi.org/10.1145/3308560.3317595.
D. Shakespeare, L. Porcaro, E. Gómez, and C. Castillo. Exploring artist gender bias in music
recommendation. coRR, Sept. . URL http://arxiv.org/abs/2009.01715.
A. Singh and T. Joachims. Fairness of exposure in rankings. In Proceedings of the th ACM SIGKDD
International Conference on Knowledge Discovery & Data Mining, KDD ’, pages –, New
York, NY, USA, . ACM. ISBN . doi: ./.. URL http:
//doi.acm.org/10.1145/3219819.3220088.
T. Spalding. Introducing thingISBN. https://blog.librarything.com/thingology/
2006/06/introducing-thingisbn/, June . URL https://blog.librarything.
com/thingology/2006/06/introducing-thingisbn/.
A. Starke, M. Willemsen, and C. Snijders. Efective user interface designs to increase energy-
eficient behavior in a rasch-based energy recommender system. In Proceedings of the Eleventh
ACM Conference on Recommender Systems, RecSys ’, pages –, New York, NY, USA, Aug. .
Association for Computing Machinery. ISBN . doi: ./..
URL https://doi.org/10.1145/3109859.3109902.
H. Steck. Calibrated recommendations. In Proceedings of the th ACM Conference on Recommender
Systems, pages –. ACM, Sept. . ISBN . doi: ./..
URL https://dl.acm.org/citation.cfm?doid=3240323.3240372.
J. ebault-Spieker, B. Hecht, and L. Ter veen. Geographic biases are ’born, not made’: Exploring
contributors’ spatiotemporal behavior in OpenStreetMap. In Proceedings of the ACM Confer-
ence on Supporting Groupwork, pages –. ACM, Jan. . ISBN . doi: ./
.. URL https://dl.acm.org/citation.cfm?doid=3148330.3148350.
M. elwall. Reader and author gender and genre in GoodReads. Journal of Librarianship and Infor-
mation Science, ():–, June . ISSN -. doi: ./. URL
https://doi.org/10.1177/0961000617709061.
M. van Alstyne and E. Brynjolfsson. Global village or Cyber-Balkans? modeling and measuring
the integration of electronic communities. Management Science, ():–, June . ISSN
-. doi: ./mnsc... URL http://mansci.journal.informs.org/
cgi/content/abstract/51/6/851.
S. Vargas and P. Castells. Rank and relevance in novelty and diversity metrics for recommender
systems. In Proceedings of the Fith ACM Conference on Recommender Systems, RecSys ’, page
–, New York, NY, USA, . ACM. ISBN . doi: ./..
URL http://doi.acm.org/10.1145/2043932.2043955.
VIDA. e VIDA count | VIDA: Women in literary arts. http://www.vidaweb.
org/the-2016-vida-count/, Oct. . URL http://www.vidaweb.org/
the-2016-vida-count/. Accessed: --.
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski,
P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman,
N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, I. Polat, Y. Feng, E. W.
Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, E. A. Quintero, C. R.
Harris, A. M. Archibald, A. H. Ribeiro, F. Pedregosa, P. van Mulbregt, and SciPy . Contrib-
utors. SciPy .: fundamental algorithms for scientific computing in python. Nature methods,
():–, Mar. . ISSN -, -. doi: ./s- - - . URL
http://dx.doi.org/10.1038/s41592-019-0686-2.
M. Wan and J. McAuley. Item recommendation on monotonic behavior chains. In Proceed-
ings of the th ACM Conference on Recommender Systems, pages –. ACM, Sept. . ISBN
. doi: ./.. URL https://dl.acm.org/citation.cfm?
doid=3240323.3240369.
M. C. Willemsen, M. P. Graus, and B. P. Knijnenburg. Understanding the role of latent feature
diversification on choice dificulty and satisfaction. User ModelingandUser-Adapted Interaction,
():–, Oct. . ISSN -, -. doi: ./s- - - . URL https:
//link.springer.com/article/10.1007/s11257-016-9178-6.
K. Yang and J. Stoyanovich. Measuring fairness in ranked outputs. In Proceedings of the th Inter-
national Conference on Scientific and Statistical Database Management, number Article in SSDBM
’, pages –, New York, NY, USA, June . Association for Computing Machiner y. ISBN
. doi: ./.. URL https://doi.org/10.1145/3085504.
3085526.
S. Yao and B. Huang. Beyond parity: Fairness objectives for collaborative filtering.
In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan,
and R. Garnett, editors, Advances in Neural Information Processing Systems , pages
–. Curran Associates, Inc., . URL http://papers.nips.cc/paper/
6885-beyond-parity-fairness-objectives-for-collaborative-filtering.pdf.
M. Zehlike, F. Bonchi, C. Castillo, S. Hajian, M. Megahed, and R. Baeza-Yates. FA*IR: A fair top-
k ranking algorithm. In Proceedings of the ACM on Conference on Information and Knowledge
Management, CIKM ’, pages –. ACM, Nov. . ISBN . doi: ./
.. URL http://dl.acm.org/ft_gateway.cfm?id=3132938&type=pdf.
C.-N. Ziegler, S. McNee, J. A. Konstan, and G. Lausen. Improving recommendation lists through
topic diversification. In Proceedings of the th International Conference on World Wide Web, pages
–, Chiba, Japan, . ACM. ISBN . doi: ./.. URL
http://portal.acm.org/citation.cfm?id=1060745.1060754.

0
1
2
3
Density
AZ
Smoothed Predicted y/n Observed y/n
0
0.5
1
1.5
2
BX-E
0
0.5
1
1.5
BX-I
0
0.5
1
GR-E
0 0.25 0.50 0.75 1
Profile Proportion of Female Authors
0
0.5
1
GR-I
Figure : Distribution of user author-gender tendencies. Histogram shows observed proportions;
lines show Gaussian kernel densities (bandwidth 1/2 of Scott estimate) of smoothed tendencies
(θ
0
) along with obser ved and predicted proportions.

0
0.5
1
1.5
2
Density
AZ
Smoothed Predicted Observed
BX GR
ALS
0
0.5
1
1.5
BPR
0
0.5
1
1.5
2
II
0 0.25 0.50 0.75 1
0
1
2
3
0 0.25 0.50 0.75 1 0 0.25 0.50 0.75 1
Recommender Proportion of Female Authors
UU
Figure : Posterior densities of recommender biases from integrated regression model (implicit
feedback).

0
3
6
9
Density
AZ
Smoothed Predicted Observed
BX GR
ALS
0
2
4
6
II
0 0.25 0.50 0.75 1
0
1
2
3
4
5
0 0.25 0.50 0.75 1 0 0.25 0.50 0.75 1
Recommender Proportion of Female Authors
UU
Figure : Posterior densities of recommender biases from integrated regression model (explicit
feedback).

Figure : Scatter plots and regression cur ves for implicit feedback recommender response to in-
dividual users. Points are observed y/n proportions; cur ves are regression lines transformed from
log-odds to proportions. Rug plots show marginal distributions.

Figure : Scatter plots and regression curves for explicit feedback recommender response to indi-
vidual users. Points are obser ved y/n proportions; curves are regression lines transformed from
log-odds to proportions. Rug plots show marginal distributions.

0.50
0.25
0
0.25
Intercept
ALS
Set
AZ
BX
GR
BPR II UU
Explicit
0 0.5 1
0.50
0.25
0
0.25
0 0.5 1 0 0.5 1 0 0.5 1
Slope
Implicit
Figure : Slopes and intercepts for recommender models, with % inter vals for the parameter
estimate (slope intervals are narrower than the position dots). Dashed lines show perfect propa-
gation (slope=, intercept=).

Figure : Top-N accuracy of natural recommenders and the Forced Balance strategies.
